
INTRODUCTION:
Copying and pasting code (“copy-paste”) is a primitive but very common form of software re-use. Unfortunately, this practice is fraught with dangers not least of which is duplicating bugs and security defects throughout the system. While the degree to which copy-paste, as a general code construction technique, should be allowed or disallowed is debatable, everyone can agree that errors introduced via inconsistent modifications to copied code are bad. Human programmers can detect some instances of copy-paste manually, at least in fairly small code bases. Doing this is not too difficult for an automated tool, even for large programs (though it can be tricky when the copies are modified, as frequently happens). However, detecting only those instances of copy-paste that introduce outright errors is much harder, even for an automated tool, and is exceptionally difficult to do manually (for reasons having to do with perceptual psychology). In this post, I’m going to show examples of GrammaTech’s CodeSonar detecting tricky copy-paste errors and how this is useful for improving quality and security.
Related:
- Anti-patterns: Cut-And-Paste Programming
- The Economics of Static Analysis Tool Usage
- Is Copy and Paste Programming Really a Problem?
Copy and Paste: We keep doing it and we know better
Most developers would agree that simply copying and pasting code is a poor form of re-use and a bad practice in general. However, it is common because proper re-use takes extra time and money (in the short term). This might be due to a lack of motivation for proper re-use and lack of forethought. Whatever the excuse, there’s plenty of reasons to minimize copying and pasting, for example:
- Poor reuse: The real cost of developing software is not in the typing of the code, so simply duplicating code does little to increase productivity. Duplicating bugs over and over makes matters worse. In addition, the opportunity for collecting and documenting useful, reusable code is lost. Creating more code moves your code coverage metrics in the wrong direction and increases your testing burden.
- Duplicating bugs and security vulnerabilities: The most obvious problem is duplicating the problems inherent in the original code throughout the project. Worse still is that each copied version is usually modified for its specific context, making tracking down the bugs more difficult.
- Introduce new errors: After code is copied it’s usually modified to suit its new location. Such modifications are typically a manual editing process and are thus prone to all of the sorts of human errors that plague any repetitive, manual task. These edits are often made hastily, without a full understanding of the original code, allowing for subtler semantic errors.
Licensing issues
Code can be as easily copied and pasted from online examples or open source projects as it can from internal projects. Not understanding the license implications of copied source can be very problematic, more so for embedded devices, where onboard software is considered a new and unique copy. This is not an area that GrammaTech specializes in but other companies do provide tools for these types of analysis.
How advanced static analysis helps detect tricky copy and paste bugs
A tool that just detects instances of copy-paste is useful for those looking to restructure existing, working code, of course, but it would be a very blunt instrument: developers wouldn’t know where to start. Even among those not looking to cleanse copy-paste sins of the past there’s interest in finding actual errors in the code. Advanced static analysis can focus on finding such copy-paste errors, cases where code was re-used but new errors were introduced in the process. Such errors are typically introduced during variable substitution, the process where the pasted code is adjusted to its new context.
This is a tricky analysis to do. The analysis tool has to first find re-use patterns across large spans of code and then find places where incomplete substitution of variables has been done in the pasted code compared to the source location. Even this is not sufficient evidence to report an error, since there are many reasons why a seemingly-inconsistent modification was exactly what the programmer intended and is perfectly correct. One must go much farther and try to see into the mind of the programmer to see whether their likely intent matches the code they actually wrote. It needs to do this with high precision, as we’ve discussed before in a previous post.
Examples
The following examples are real errors that were found using GrammaTech CodeSonar on open source projects.
Postgres
In this example a 16-line block of code was copied and pasted, and a variable changed, but not consistently – the txn pointer in the copy is incorrect and should be cur_txn. We informed the development team and they changed the code as suggested by the warning shown in Figure 1.
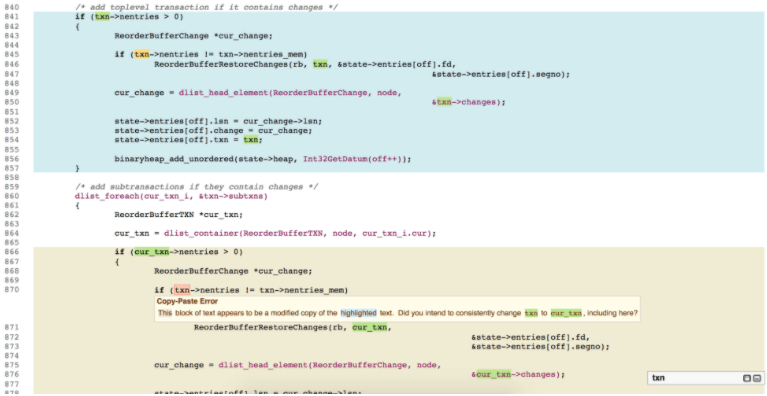
Figure 1: Bug #14208 in file: postgresql-9.4.4/src/backend/replication/logical/reorderbuffer.c.
FFmpeg
Figure 2 shows CodeSonar’s detection of a copy-paste error in FFmpeg (an open source video transcoder) where the copied code was not updated consistently, left with the field dts in the expression pkt->dts instead of the correct pts.
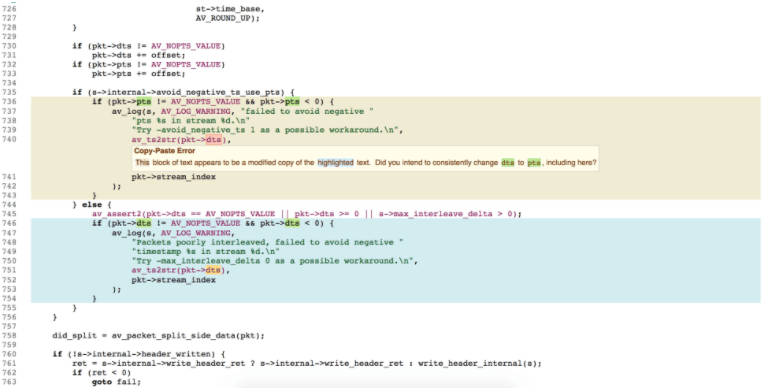
Figure 2: Copy and paste error detected in file FFmpeg/libavformat/mux.c.
Open Office
Another example was found in OpenOffice where code was copied and pasted incorrectly. The difference in the correct variable NSizY compared to NSizX is subtle and easily overlooked in the original code, but note here how the presentation of this problem in CodeSonar makes it very clear. This bug was submitted to the OpenOffice project recently and has not been addressed yet.
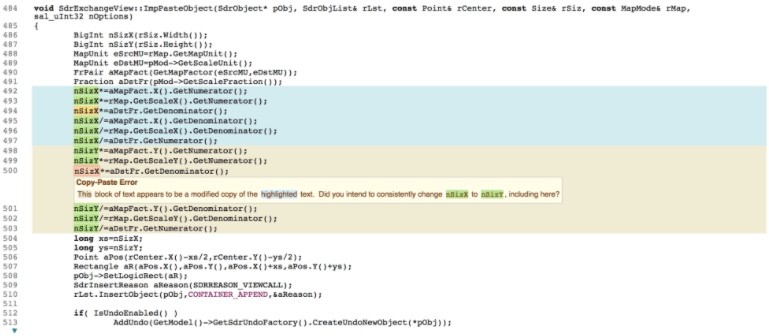
Figure 3: Issue 127449 in file: main/svx/source/svdraw/svdxcgv.cxx.
Llvm
This example shows how copy-paste errors are detected even in string literals, often in conjunction with patterns discernible in nearby code. In this case a very large block of code – an entire class definition with numerous member function bodies included in it – was copied, so Figure 4 only shows a portion of the original code and a portion of the copy.


Figure 4. llvm bug 34996 in file: libcxx/include/list.h.
Internal testing of GrammaTech’s Copy-Paste Error detection has found more than twenty different confirmed bugs in seven different open source packages plus at least five more bugs that are pending review by the maintainers of various packages. The affected packages include linux, chromium, mysql, wine, eclipse TCF, python, and postgres.
CONCLUSION:
Copying and pasting code is the most common form of re-use in software development despite the problems it creates. While real factoring and reuse is usually preferred, for legacy code it may not be practical, so use of advanced static analysis is key to finding the errors frequently resulting from this practice before they make it into the final product (as they have in the examples). As with all static analysis, finding problems in the code soon after they’re introduced, before expensive testing effort is spent on them, is to everyone’s advantage. Simple tools that detect copied and pasted code for its own sake will create a lot of work for you, with relatively little to show for it. An advanced static analysis tool that only shows you real, often subtle, errors in the copied code points you right at the changes that need to be made, maximizing your return on your development investment.
Finally, I would like to acknowledge the outstanding contributions of Dr. Petru-Florin “Pepi” Mihancea, without which this project would be nowhere near where it is today. Dr. Mihancea is an associate professor at Polytechnic University in Timisoara, Romania, though this work was unrelated to that position.
Interested in learning more? Read our guide on Advanced Static Analysis for C++
{{cta(’42fd5967-604d-43ad-9272-63d7c9d3b48f’)}}