Introduction
Several of us at GrammaTech, along with many talented people from UVA, recently participated in DARPA’s Cyber Grand Challenge (CGC) as Team TECHx. The challenge in CGC was to build an autonomous Cyber Reasoning System (CRS) capable of playing in a “Capture The Flag” (CTF) hacking competition. Our system was called Xandra.
Each system was responsible for defending network services while proving vulnerabilities (“capturing flags”) in other systems’ defended services.
The challenge started back in 2014. In two years, what was initially over 100 teams whittled down through qualifying events to just 7 teams in the final event. During the final event, DARPA distributed Challenge Binaries (CBs) that implemented network services and that had been specifically crafted to have different vulnerabilities1. Each CRS was responsible for fielding a version of each of these CBs, which could be attacked by competitor CRSes. The trick was that CRSes could both re-write CBs to make them less vulnerable while simultaneously trying to exploit the vulnerabilities in other systems’ CBs. Each time a CRS was able to successfully attack another CRS’s CB, it gained points. Each time a CRS’s fielded CB was successfully attacked, it lost points. In the end, our system, Xandra, did very well (2nd place!) with what I would classify a combination of good defense, good availability, and average offense.
{kind=link}
 Xandra on the CGC stage.
Xandra on the CGC stage.
A lot has been written about the competition by other teams already (Mayhem 1, Mayhem 2, Shellphish, CodeJitsu). As the finalists have provided their opinions, it’s interesting to learn that much of what we did on the offensive side was in the same vein as many other competitors. At least three other teams used AFL, a very cool grey-box fuzzing tool originally released by Michal Zalewski out of Google. Like many of the other competitors, we supplemented AFL’s “fast” abilities with the “smarts” of our own in-house symbolic execution engine, called Grace. Other competitors seem to have had some superior exploit-generation technology (particularly galling for me since that was my department); however, the offensive area where we did seem to excel was speed in finding exploits. When Xandra found an exploit, it did so very quickly, and this speed allowed us to rack up the points.
The Interesting Stuff
One portion of our system that seems to be unique (or at least not yet discussed in other blog posts) is the way that we used the resources provided by DARPA to drive our various analyses.
But first, a bit of background. DARPA designed the CGC competition to mimic the Software as a Service model2, where the teams had an ability to monitor how users were interacting with their servers. In order to evaluate modified CBs, DARPA required the CB writers to provide, along with the binary itself, a generator which could generate millions of sample interactions. These sample interactions served two purposes: (1), they allowed DARPA to detect when a program that had been re-written for defensive purposes had been broken, and (2), it provided a rich set of sample inputs to seed the search for crashes and vulnerabilities.
In the competition, DARPA provided the raw network tap for these interactions with fielded CBs. This quickly could become thousands of PCAP files for each CB, which was great since many forms of analysis, such as fuzzing, are much more powerful when given a large and diverse set of seed inputs.
Feeding these inputs directly into an analysis system, however, has two drawbacks.
First: Swamped by Inputs
First, and most obviously, the various analyses could quickly become swamped by the sheer number of (often repetitive) inputs. In order to handle this challenge, we created a modified instance of AFL to act as a gate-keeper. This instance would run through each of the incoming PCAP files and evaluate whether they brought anything “new” to the table. To more formally define “new,” we used AFL’s internal coverage metrics (discussed here). Any input which increased the coverage would be added to the pool of “interesting” inputs that our other analyses drew from.
This process of filtering away “uninteresting” inputs was of particular importance for Grace. For those of you who haven’t used it before, symbolic execution engines are often very slow, especially once any depth of exploration has been achieved. By limiting the number of inputs, we allowed Grace to focus on unique and interesting inputs, rather than churning away at things that would likely lead down previously-explored paths.
Second: Authorization Tokens
The other reason that feeding the inputs directly into the analysis system might not work is that these inputs might depend on the value of some randomly generated token.
A Quick Example
For example, consider the example program KPRCA_00001, provided by DARPA prior to the qualifiers. This program provides users with an ID that they have to use in order to log into the system and access the functionality the program provides.
An example interaction with the program looks something like this:
- USER: HELLO
- SERVER: OK 5CF98744
- USER: AUTH 5CF98744
- SERVER: OK
- USER: SET mode encode
- SERVER: OK
- …
In this case, the user logs into a system using a randomly-generated token provided by the server3. Naively running this program with AFL, looking for whether it expands coverage or not, will almost certainly miss the potential exploratory power of the input. This is because the security token is based on some unknown random seed. Running this same interaction on a different computer would result in the following interaction:
- USER: HELLO
- SERVER: OK 49F589F7
- USER: AUTH 5CF98744
- SERVER: ERROR 403
- USER: SET mode encode
- SERVER: ERROR 403
As can be seen, now that a new random token is provided, the analysis is no longer able to follow the path traversed during the original run, when the input and output were captured. In this instance, it is extremely unlikely that AFL could “guess” the correct authorization token, meaning that all of the PCAP files would follow the same path to “ERROR 403.” Therefore, almost none of the thousands of sample PCAP files would result in new coverage (according to AFL) and therefore almost none would be added to the pool of “interesting” inputs.
When running a simulation of the competition with this particular program, only the first few of the thousands of inputs that are generated gets through to the rest of the analysis (each one that passes through is “interesting” only in the number of times it fails).
A Fast Solution
In order to handle this problem, we added an additional stage to the gate-keeping instance of AFL. AFL normally works by taking some input, tweaking it slightly, and running it to see if the input increases the amount of program covered. Our new stage compared the expected output, seen in the PCAP file, with the actual output of the program. It then attempted to identify the location of suspected authorization tokens in the input using the following formalization:
(Tokenize(expected_input)) ∩ Tokenize(input)) Set(actual_output)
Where the function Tokenize takes an array of characters and produces a set of of those characters broken up into tokens.
Intuitively, the process looks for tokens that are in both the input and the output of the PCAP file. (For non-ascii programs, such as for program that simulated a storage device, we did something similar but instead of breaking things up into tokens, we looked for common subsequences above a certain minimum length.) This shows that there were likely tokens that had to be parroted back to the system. The process then kept only those tokens that were not in the actual computed output. This showed that the token was based on some non-deterministic behavior.
With this set of suspected authorization tokens, the processes then pick tokens from the actual output as potential replacements. Here, we used various heuristics, since you couldn’t assume that the authorization token would be in the same place or would even be the same length. This is where the choice to use AFL really paid off. AFL is really fast. Therefore, the process could run through thousands of suspected/replacement token pairs.
In many cases it was possible to know once the correct authorization token was used. For example, in the KPRCA_00001 example above, the actual output would go from “ERROR 403” to “OK.” This is clearly an improvement because the actual output now matches the expected output. It is possible, however, that there is some randomness in the output that is not used for authorization. In this case, the expected output and the actual output might never fully match. Therefore, it is possible that we are never sure that we have found the correct authorization token. Here, we rely on AFL, specifically its coverage metrics. If replacing the suspected authorization token results in increased coverage, then we add it to the pool of “interesting” inputs. While this changes our search from one that attempts to traverse the “same” path as the PCAP file to just a search for “new” and interesting paths, this view is actually more useful from AFL’s perspective. Not only are we able to identify tokens that traverse the “same” path as the one followed by the original PCAP file, but there is also the possibility of finding other interesting paths.
Think Global, Fuzz Local
There is one final caveat to this whole process: multiple authorization tokens. These could take the form of the same authorization token being used repeatedly throughout the interaction or new authorization tokens being given during a single interaction. This additional complexity requires us to view the coverage achieved by a particular PCAP file from both a global and local perspective. The goal of examining each PCAP file for authorization tokens is to increase the global coverage of the “interesting” inputs that the other analyses are working on. In order to achieve this goal in the context of multiple authorization tokens, however, we must examine the coverage for each individual PCAP file. An example of where this might matter is a PCAP file that has multiple authorization tokens where only breaking through the final authorization token allows us to increase the global coverage.
In order to handle this extra complexity, we kept track of both the local coverage achieved via mutating a particular PCAP file (as well as its suspect/replacement mutants) and the global coverage achieved by every PCAP file (as well as their mutants). Every time we tried a new suspected/replacement token pair, we evaluated it against two coverage metrics. First, we evaluated it to see whether it increased global coverage. If it did, then the input was immediately added to the pool of “interesting” inputs for the other analyses to chew on. In addition, we also evaluated it to see if it increased the local coverage of the particular PCAP file. If it did, then we continued to analyze it with the hope that we could break through to some previously unseen part of the program. By repeatedly iterating on this process, we were able to incrementally pass successive authorization tokens.
Formalization
In a more formal sense, this authorization token identification process can be thought of as extending AFL’s body of fuzzing mutators. Whereas the pre-existing mutators worked by flipping individual characters or adding words from a pre-existing dictionary, this mutator drew on a set of PCAP inputs and fuzzed them by gathering differences between the expected output and the actual output.
Putting it All Together
With this setup, we addressed the two problems associated with the PCAP inputs provided by the network: too much information resulting in swamping other analysis systems and the presence of authorization tokens based off unknown random seeds. In the end, our system looked something like the figure below.
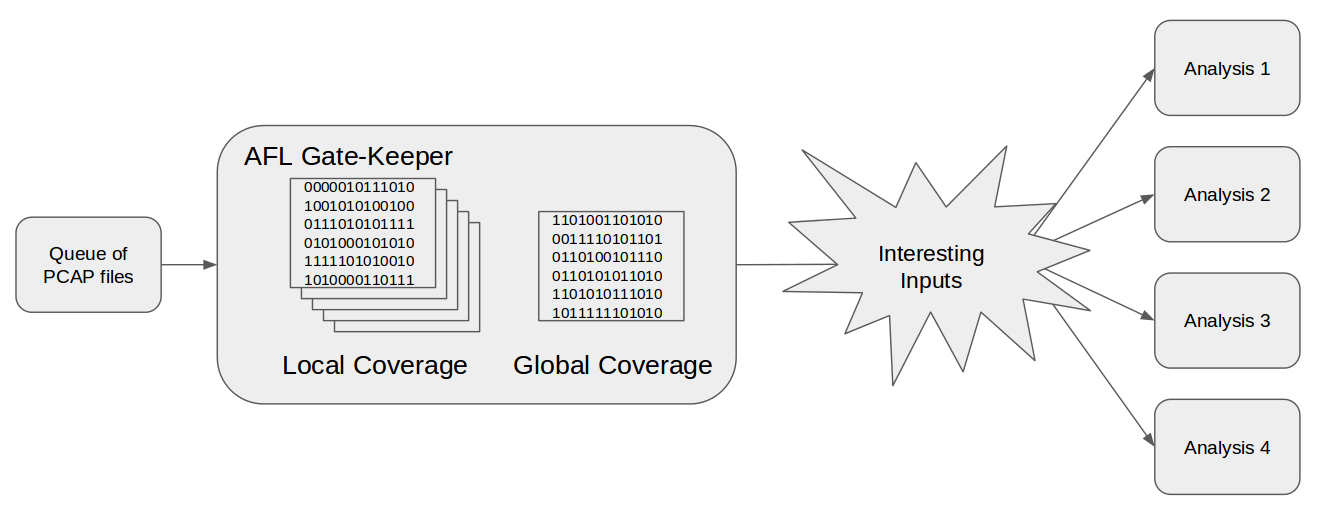
The first part of the diagram is the “Queue of PCAP files,” illustrated on. This queue is filled with sample PCAP inputs captured off of the network. The gate-keeper instance of AFL grabs items from this queue and evaluates them (it is during this evaluation that we attempt to bypass any authorization tokens). If, during the evaluation, an input is found that increases the global coverage tracked by the gate-keeper, then that instance is forwarded to the pool of “interesting” inputs from which other analyses draw.
Conclusion
The CGC competition was designed to give the program analysis systems a vast store of information with the hopes that computer systems could automatically patch and exploit vulnerabilities in programs. There has been a lot of documentation by other teams on how they attacked this particular problem. I believe that an important, as of yet undocumented, part of this competition was the ability to properly utilize the sample inputs provided over the network. Doing so in a way that maximized the utility of each input while simultaneously filtering out repetitive data gave underlying analyses the best chance of succeeding.
On a more personal note, the CGC competition was one of the most rewarding professional experiences I’ve ever had. Not only did I have the opportunity to work with (and compete against) some of the best in the business, but I felt like I was contributing to a process that was truly pushing the state of program analysis forward.
Footnotes:
1: In total DARPA created 213 binaries for the competition, 131 for the qualifiers and 82 for the final event. These programs were written for a simplified binary format, called DECREE, that has only seven system calls. This dramatically reduced number of system calls both made analysis easier and rendered the systems useless if they should somehow escape into the wild.
Trail of Bits (one of our competitors) rewrote these binaries into normal Linux so that the research community can more easily analyze them, which, we all agree, was very nice of them.
2: Another interesting model to test would be the more traditional one of releasing the binaries to users and then having the user interact with unsafe content on their own computer. This would provide less information to the developer/maintainer of the program about how their program was being used, making it more difficult to differentiate between the average user and a malicious user.
3: A less contrived example of this is might occur when a user logs into a website. The website could give them a randomly generated token that is required to be presented whenever they move through a secure section of the site.