
A LOT of code has been written – enough for LOT to deserve caps. By DARPA’s estimate, it is in the order of hundreds of billions of lines of open-source code, and I am probably safe in conjecturing that there is a LOT more proprietary code. And just like how history repeats itself, software repeats itself, in some form or the other.
In a spirit similar to history, mistakes in software are also often repeated. For example, people have tried to parse HTML using regular expressions again and again, prompting one of the funniest stackoverflow answers I have seen. The business of a static analysis tool is premised on developers making the same kind of mistakes and vulnerabilities, and the fact that programming without errors remains a hard problem.
You don’t have to take my word that software is repeated. Gabel and Su[1] studied how unique really is software. They looked at 420 million lines of source code, and asked this interesting question: if you were writing a new program, and you could only copy paste from existing programs, how far could you get? They found software to be heavily redundant at smaller block sizes (size of the copy pastes) of 1-7 lines, and less redundant with increasing block sizes.
Developers copy-pasting code is quite common. Stacksort is a parody mimicking the cynical view of the software development process these days: it looks up stackoverflow for sorting routines and tests them until something seems to work. While it was meant to be a comic-based joke, together with the availability of large amounts of code, it inspires the following question: can the vast amount of human knowledge amassed in the form of code be exploited to improve the quality, correctness, security and experience of programming?
The MUSE Program
DARPA’s initiative called MUSE does exactly that. MUSE has received a lot of sensational coverage (Engadget, Computer World) in the press, and various views have been expressed on what this program seeks to do. Newsweek questioned if computer programming is a dying art, The New Yorker questioned the need to learn coding, Popular Science called it autocomplete for programmers, Wired and Engineering asked if computers would start writing their own code.
For the MUSE program, GrammaTech has joined forces with researchers at Rice Univerity, UT Austin, and University of Wisconsin-Madison to develop PLINY. The vision of PLINY is to be the next-generation software engineering tool that learns from the plethora of code that I mentioned above. PLINY can be thought of as a guide to the developer, letting developers take more of a supervisory role in programming. PLINY is aimed to help in constructing, debugging, verifying, maintaining, and repairing code. To enable this vision, everything from superficial syntax to deep semantic facts about vast amounts of code must be learned, potentially having a major impact on how future code will be written.
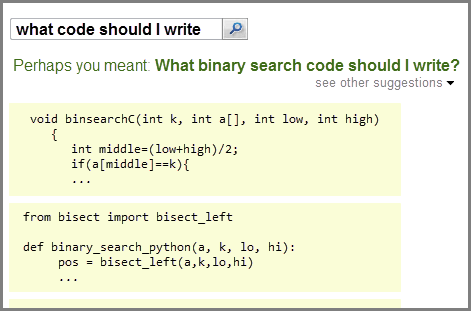
The MUSE program has been compared to auto-complete (for example, when Google search automatically prompts you what you want to search for based on what you have typed so far) and auto-correct (for example, when your text messenger automatically decides to correct your spelling). Such systems for for natural languages have had limited success, providing enough fodder for Internet ridicule. But, in a large-scale study, Devanbu[2] found that programs are approximately 8-32 times more predictable than English text!
After getting over an initial surprise, I realized that the numbers make sense. Let’s say you randomly took paragraphs from different books in a large library, and randomly took pieces of code from different projects. It is likely that the code pieces would have more commonality than the English text because code has a lot more structure, and developers use common idioms more often than not. This is an argument towards MUSE — irrespective of the degree of auto-correction or auto-completion that can be achieved for coding, there is vastly untapped potential in existing code corpus, that can at a minimum improve the state of current programming practices.
I once had a professor who was terrible at spelling, but wrote excellent, persuasive papers. He said that being able to not worry about exact spellings, and relying on spell checkers/correctors, freed him to write at the speed of his thinking, allowing him to work quicker, and iterate more. Perhaps we can do the same for programming, enabling developers to increase productivity by letting them think at a higher level: searching, navigating, selecting from recommendations, and providing hints to the development system. The developers would still be in charge, using their domain knowledge and expertise, and creative understanding of the problem scenario.
For aMUSEment, I pondered about why we keep re-implementing/repeating code. I came up with the following:
- We do not know that something was already implemented.
- The requirements were slightly different: the existing implementation is not generic enough.
- Efficiency reasons: the existing implementation is not specialized enough.
- The existing version is not maintainable, we don’t understand how it works.
- The preconditions to use a piece of code is unclear.
- We tried using existing code and it did not work.
- Not invented here principle.
Maybe with the exception of the final point, I think the rest can all benefit from novel solutions that look at existing corpus of code, learn and reason using them, and provide inputs to the developer to do their job more productively.
In addition to being a challenging research problem, MUSE also poses other practical problems, like developer adoption. One of the biggest impediments to adoption of such tools is when the developer doesn’t understand a particular suggestion or a correction. This comes up a lot when using static analysis tools too — analyses use deep local and global reasoning, using approximations to find bugs. In order to understand why an analysis thinks there is a particular bug, a developer needs to reconstruct the analysis’s reasoning, at least partially, which is non-trivial. The more time it takes the developer to understand it, the more likely he will discard the analysis results.
GrammaTech has a lot experience in disseminating such analysis reasoning information (for example, by highlighting paths when followed could cause the bug), and is doing more advanced research in this area. In the case of MUSE, this issue is aggravated — the reasoning for a suggestion could be based on a large code corpus, together with intricate learning and probabilistic reasoning. All in all, we have our hands full with hard problems to solve.
TL;DR
- There is a lot of code available, that we can look at, learn from, and build tools that drastically improve the code development process.
- If you are a software engineer, NO, you are not going to be obsolete, at least not in the near future.
References:
- Gabel, M., & Su, Z. A study of the uniqueness of source code. In FSE 2010.
- Devanbu, P. New Initiative: The Naturalness of Software. In ICSE NIER Track 2015.