Software is big. Cheap memory and fast CPUs have allowed programmers to create applications with millions of lines of code. These large programs are vastly complex systems that are impossible to completely understand. Anyone who has worked on a big program knows how it starts to feel like an organic being — poke one part and you can’t be sure how it will react.
Big software systems are hard to work with because interdependencies are woven throughout the system. Much of software engineering is dedicated to dividing software systems into ‘independent’ modules, limiting the dependencies. Unfortunately, in practice this still leaves so many subtle dependencies that changes in one module often disrupt other modules in unexpected ways.
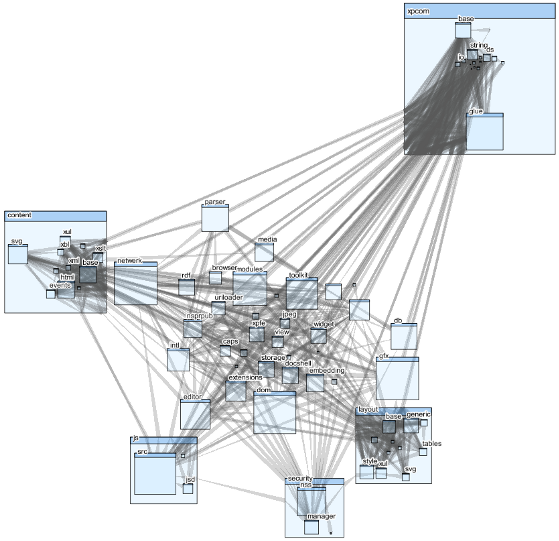
Call dependencies in Firefox web browser (shown with CodeSonar’s visualization tool).
Even in well-architected software, an apparently innocuous change in one procedure can have wide-ranging effects on performance, reliability, security, or maintainability.
This problem is partly due to our software engineering tools. The mainstay of software development is the editor, which usually shows no more than 100 lines of code on the screen. It is hard to keep in mind millions of lines of code when you’re just looking at 0.01% of the system. Of course, even if we could show a million lines of code in an editor window, it wouldn’t help much — there’s enough complexity in 100 lines of dense code to keep you fully occupied. The main bottleneck here is the human mind — there’s only so much complexity we can keep in our head at one time.
Fortunately, automation can help. Computers do not have the same bottlenecks as brains, so tools have evolved that detect problems that are not obvious when you are staring at 100 lines of code. Some examples include the following:
- Compilers flag type mismatches and other simple inconsistencies.
- IDEs show call-trees and code outlines to help programmers see the big picture. They also do their own consistency checks.
- Static analysis tools quickly analyze a large number of execution scenarios and report problems they find.
- Visualization tools show large systems.
But many problems still slip through. Particularly tricky is code that is not obviously good or bad, and has potentially wide-ranging effects.
Consider the following code:
swap(int *x, int *y) {
int tmp;
//if (x == NULL)
// return;
tmp = *x;
*x = *y;
*y = tmp;
}
You’ve probably noticed that this code will crash if NULL is passed in as an argument. This code is risky, but may be safe in the right context. Programmers often skip checking for NULL if they are confident that NULL is not a possible value. In fact, static analysis tools like CodeSonar will not flag the code above, since code like this is so common. (CodeSonar will flag any code that calls this swap() with a NULL argument, however.) Whether this code is good or bad depends on how it is used — maybe the lack of NULL-checking is dangerous, or maybe it’s an optimization worth making.
In technical terms, the swap() procedure has the following preconditions:
x != NULL
y != NULL
If either precondition is violated, the procedure will fail. Anyone calling swap() needs to make sure both preconditions are satisfied.
These preconditions are an essential part of the swap()’s interface. In isolation, we can’t tell if the preconditions are acceptable. But by watching the code as it evolves, we can highlight changes that deserve scrutiny.
Note the commented-out code in the example above — it handles the case where x == NULL. If the code was commented-out recently, that’s a big red flag. There may be other code in the system that relies on the fact that swap() handles a NULL value for x. Compilers won’t be able to detect this mismatch between swap()’s old and new behavior. Static analysis tools might catch it if there is a straightforward example of swap() being called on a NULL argument, but there’s no guarantee of it — perhaps the NULL argument only happens after a complex chain of events that a static analysis tool will miss.
However, if we perform precondition analysis repeatedly as the software changes, we can catch the addition of a new precondition and warn the programmer. Programmers may still decide that it’s ok to ignore NULL in this case, but they will not make the change unintentionally (by, say, forgetting to re-enable error checking).
The key here is using static analysis to identify risky changes to code. The code in question is not necessarily bad enough to warrant a report from a bugfinding tool like CodeSonar, but the fact that the change is recent, and potentially dangerous, means it deserves attention from a user.
The same general approach can be used to identify a number of changes that are not necessarily bad, but deserve scrutiny:
- Adding preconditions other than non-NULLness. For example, some procedure may require that pointer arguments must point to the heap (not the stack), or that certain globals be initialized before the procedure is called.
- Adding a significant new dependency — for example, requiring a new module to be linked in.
- Changing the design pattern that applies to a procedure or method.
This is an area we are exploring in a new project at GrammaTech: static analysis to find significant changes that warrant programmer review. We’re also interested in how to best make this approach usable: give programmers feedback as soon as possible (i.e., in the IDE as they are writing code), and avoid interfering with the common changes that do not deserve attention.